Transformer
2017年火于NLP,2021年火于CV
传统word2vec有何问题?
不同词在不同语境中表达的意思不同,但是预训练好的词向量vec是不变的。
词 -> 向量 -> 模型
Attention是什么?
不同数据关注点不同,如何让计算机关注到有价值的信息。根据数据(上下文语境)让计算机找到不同的attention机制。
self-attention
词不仅仅考虑词,还考虑当前词的上下文特征,融入词向量之中,就是self-attention
self-attention如何计算
词x通过W_Q,W_K,W_V矩阵计算获得q,k,v
Queries 要去查询的
Keys 被查询的
Values 实际的特征信息
q与k分别内积表示相关性,获得分值
把分值除以向量长度,再放softmax里跑一遍获得百分比,就知道每个词的重要程度,再乘各自value,求和就得到每个词的z

multi-headed 机制
通过不同的head得到多个特征表达
将所有的特征拼接到一起
可以通过再加一层全连接层来降维
一般需要堆叠多层
Decoder端
Attention计算不同
加入了Mask机制
Transformal
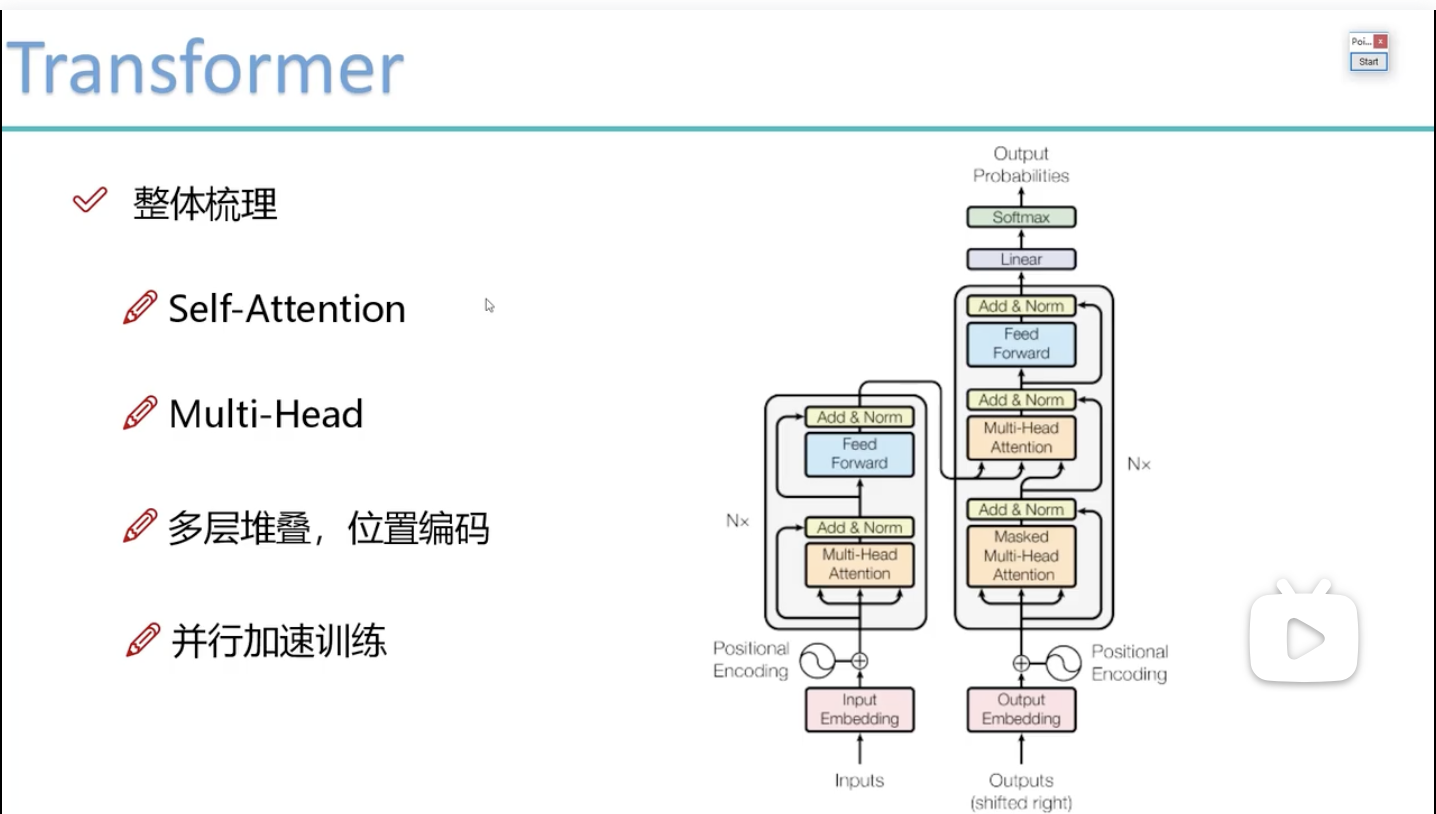
Transformal主要就是一个self-attention,其他结构和CNN类似。
关于BERT
就是transformer中的一个encoder端。
Embedding:
机器的“兴趣”向量,一般是隐含的。
用途:近邻搜索,实现内容推荐
但是当数据量大时,近邻搜索会变得很慢,可以使用Faiss(facebook AI)