机器学习-分类问题C
数学公式在渲染器中会出现错误,目前还没有解决
Outline
- Nonlinear classifiers
- Kernel trick and kernel SVM
- Ensemble Methods - Boosting, Random Forests
- Classification Summary
1 | # setup |
1 | def drawstump(fdim, fthresh, fdir='gt', poscol=None, negcol=None, lw=2, ls='k-'): |
1 | # load iris data each row is (petal length, sepal width, class) |
(100, 2)
(50, 2)
(50, 2)
1 | mycmap = matplotlib.colors.LinearSegmentedColormap.from_list('mycmap', ["#FF0000", "#FFFFFF", "#00FF00"]) |
Feature Pre-processing
Some classifiers, such as SVM and LR, are sensitive to the scale of the feature values.
- feature dimensions with larger values may dominate the objective function.
Common practice is to standardize or normalize each feature dimension before learning the classifier.
- Two Methods…
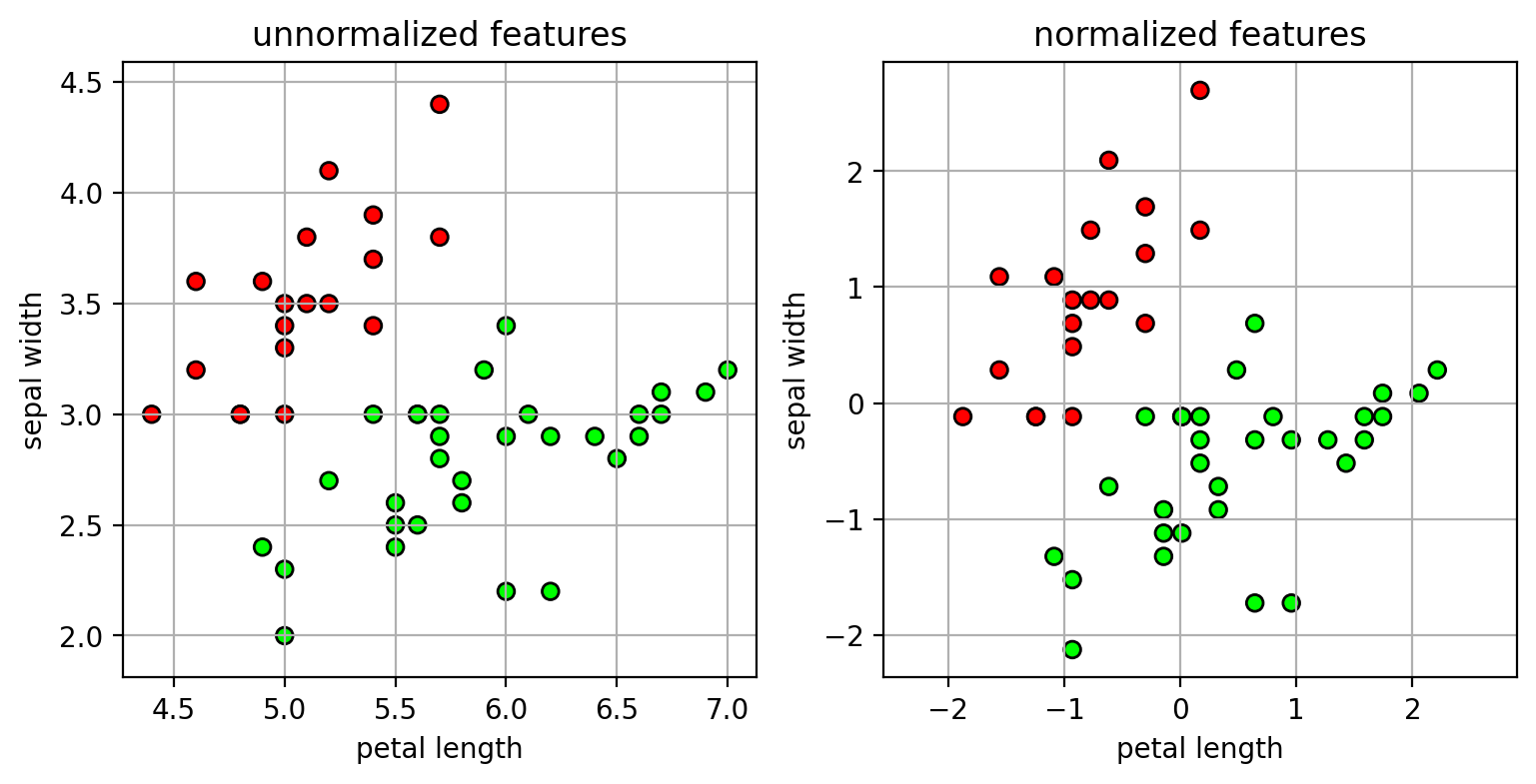
Method 1: scale each feature dimension so the mean is 0 and variance is 1.
- $\tilde{x}_d = \frac{1}{s}(x_d-m)$
- $s$ is the standard deviation of feature values.
- $m$ is the mean of the feature values.
NOTE: the parameters for scaling the features should be estimated from the training set!
- same scaling is applied to the test set.
1 | # using the iris data |
1 | nfig1 = plt.figure(figsize=(9,4)) |
1 | nfig1 |
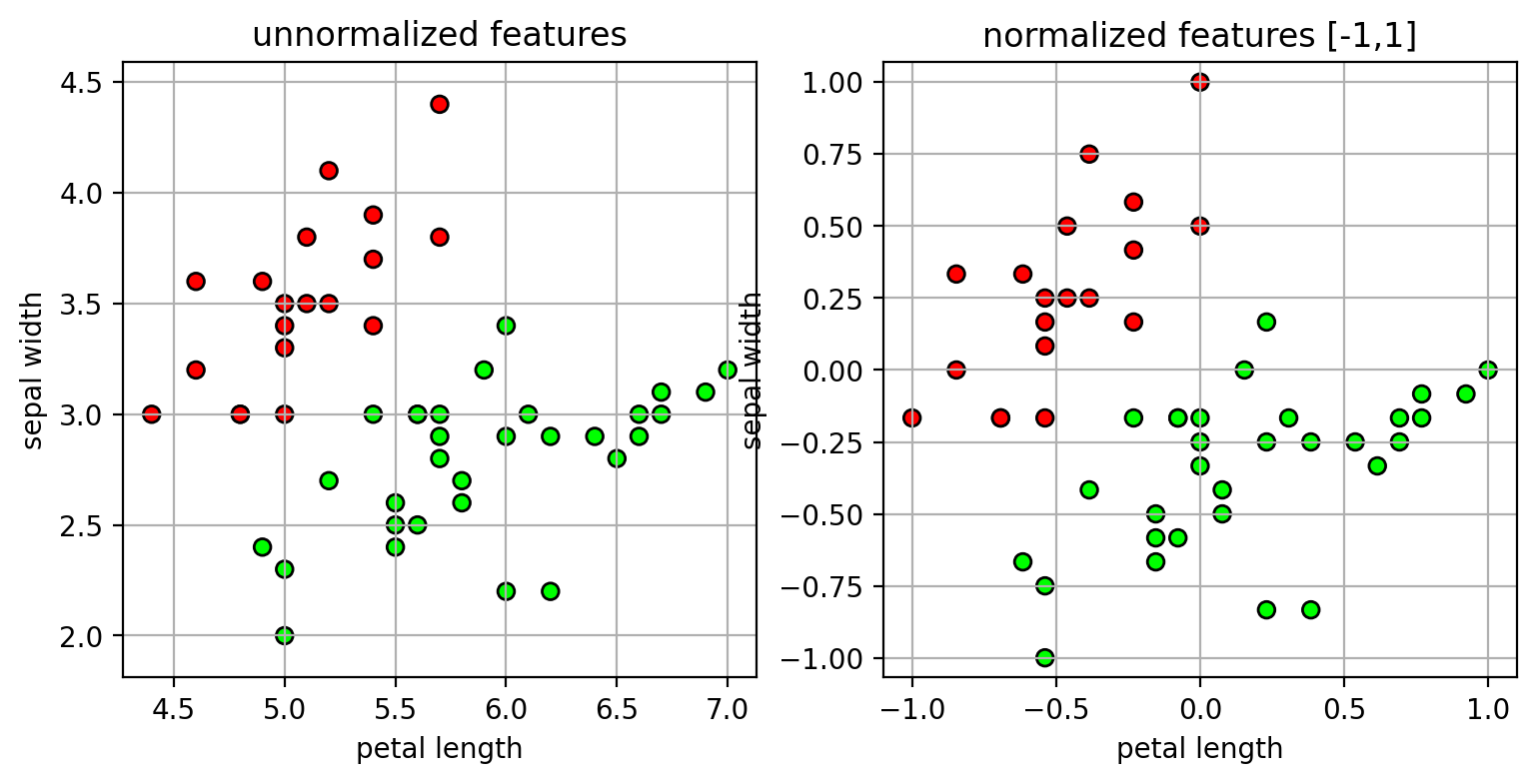
- Method 2: scale features to a fixed range, -1 to 1.
- $\tilde{x}_d = 2*(x_d - min) / (max-min) - 1$
- $max$ and $min$ are the maximum and minimum features values.
1 | # using the iris data |
1 | nfig2 = plt.figure(figsize=(9,4)) |
1 | nfig2 |
Data Representation and Feature Engineering
How to represent data as a vector of numbers?
- the encoding of the data into a feature vector should make sense
- inner-products or distances calculated between feature vectors should be meaningful in terms of the data.
Categorical variables
- Example: $x$ has 3 possible category labels: cat, dog, horse
- We could encode this as: $x=0$, $x=1$, and $x=2$.
- Suppose we have two data points: $x = cat$, $x’=horse$.
- What is the meaning of $x*x’ = 2$?
One-hot encoding
- encode a categorical variable as a vector of ones and zeros
- if there are $K$ categories, then the vector is $K$ dimensions.
- Example:
- x=cat $\rightarrow$ x=[1 0 0]
- x=dog $\rightarrow$ x=[0 1 0]
- x=horse $\rightarrow$ x=[0 0 1]
1 | # one-hot encoding example |
[array(['bird', 'cat', 'dog'], dtype=object)]
/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/sklearn/preprocessing/_encoders.py:828: FutureWarning: `sparse` was renamed to `sparse_output` in version 1.2 and will be removed in 1.4. `sparse_output` is ignored unless you leave `sparse` to its default value.
warnings.warn(
array([[0., 1., 0.],
[0., 0., 1.],
[0., 1., 0.],
[1., 0., 0.],
[0., 0., 1.]])
Binning
- encode a real value as a vector of ones and zeros
- assign each feature value to a bin, and then use one-hot-encoding
1 | # example |
/Library/Frameworks/Python.framework/Versions/3.9/lib/python3.9/site-packages/sklearn/preprocessing/_encoders.py:828: FutureWarning: `sparse` was renamed to `sparse_output` in version 1.2 and will be removed in 1.4. `sparse_output` is ignored unless you leave `sparse` to its default value.
warnings.warn(
array([[1., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 1.]])
Data transformations - polynomials
- Represent interactions between features using polynomials
- Example:
- 2nd-degree polynomial models pair-wise interactions
- $[x_1, x_2] \rightarrow [x_1^2, x_1 x_2, x_2^2]$
- Combine with other degrees:
- $[x_1, x_2] \rightarrow [1, x_1, x_2, x_1^2, x_1 x_2, x_2^2]$
- 2nd-degree polynomial models pair-wise interactions
1 | X = [[0,1], [1,2], [3,4]] |
array([[ 1., 0., 1., 0., 0., 1.],
[ 1., 1., 2., 1., 2., 4.],
[ 1., 3., 4., 9., 12., 16.]])
Data transformations - univariate
- Apply a non-linear transformation to the feature
- e.g., x $\rightarrow$ log(x)
- useful if the dynamic range of x is very large
Unbalanced Data
- For some classification tasks that data will be unbalanced
- many more examples in one class than the other.
- Example: detecting credit card fraud
- credit card fraud is rare
- 50 examples of fraud, 5000 examples of legitimate transactions.
- credit card fraud is rare
1 | # generate random data |
1 | udatafig |
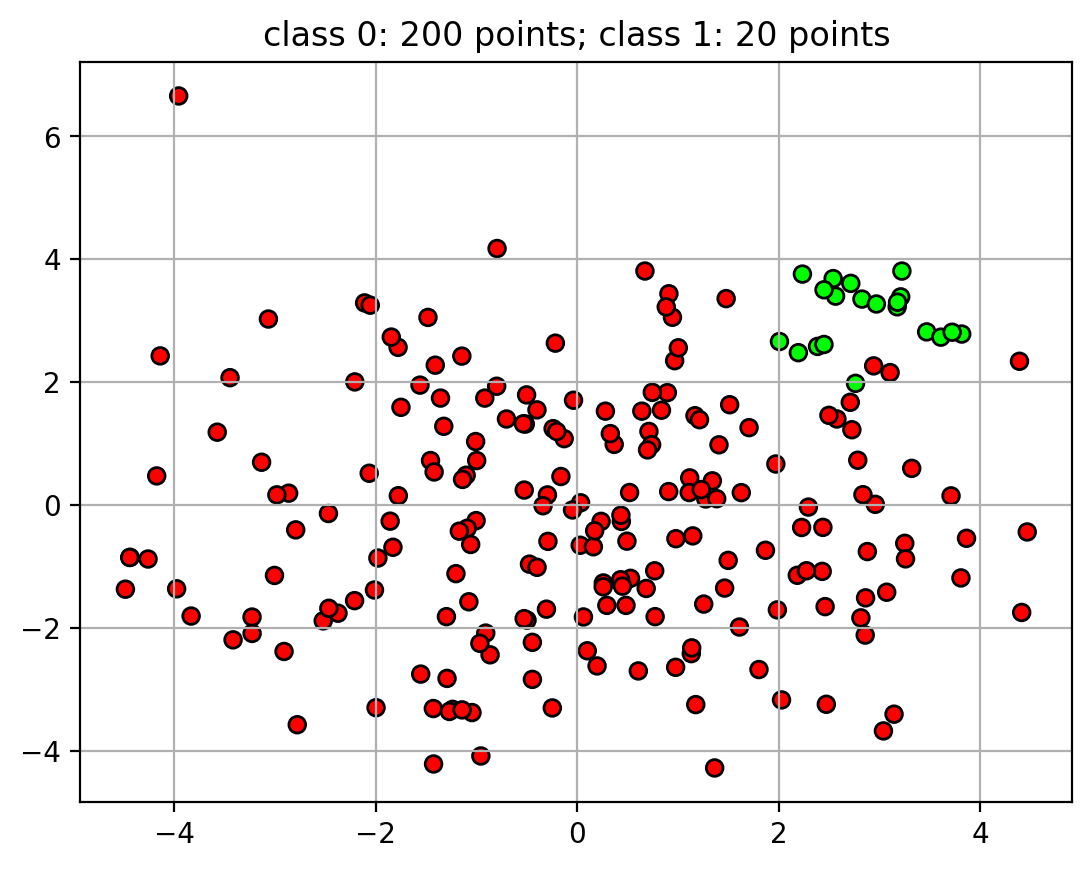
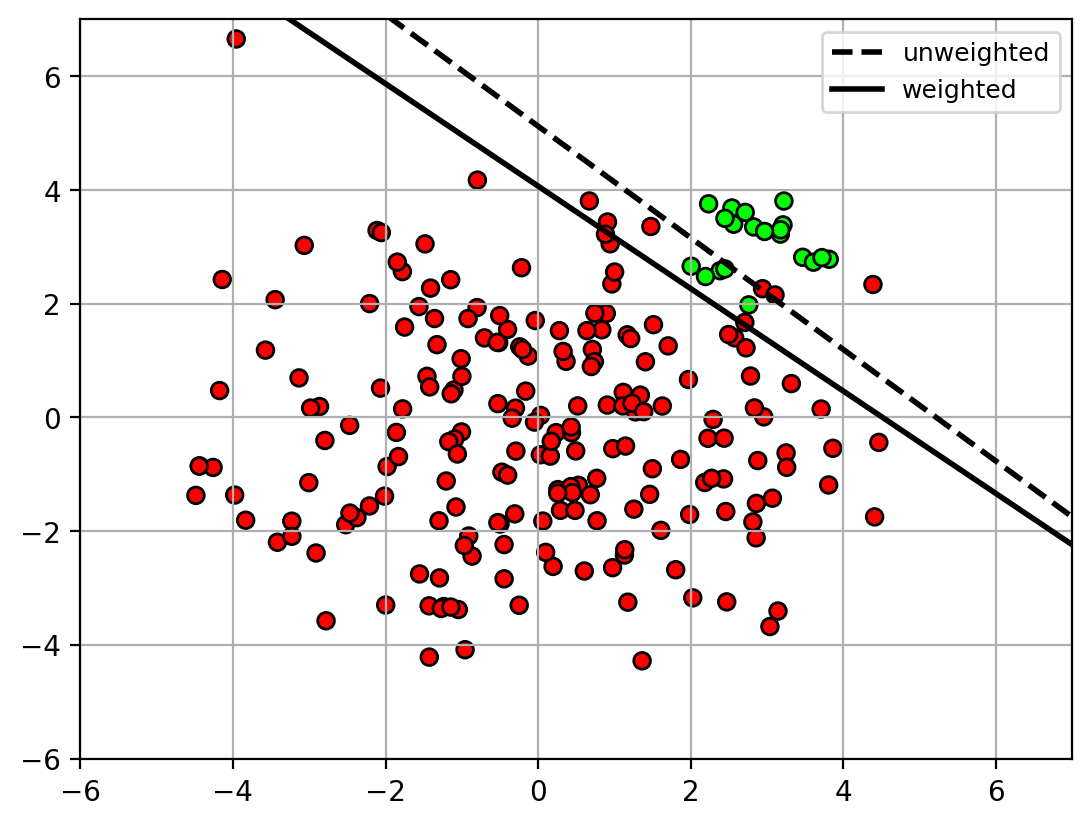
- Unbalanced data can cause problems when training the classifier
- classifier will focus more on the class with more points.
- decision boundary is pushed away from class with more points
1 | from sklearn import svm |
1 | udatafig1 |
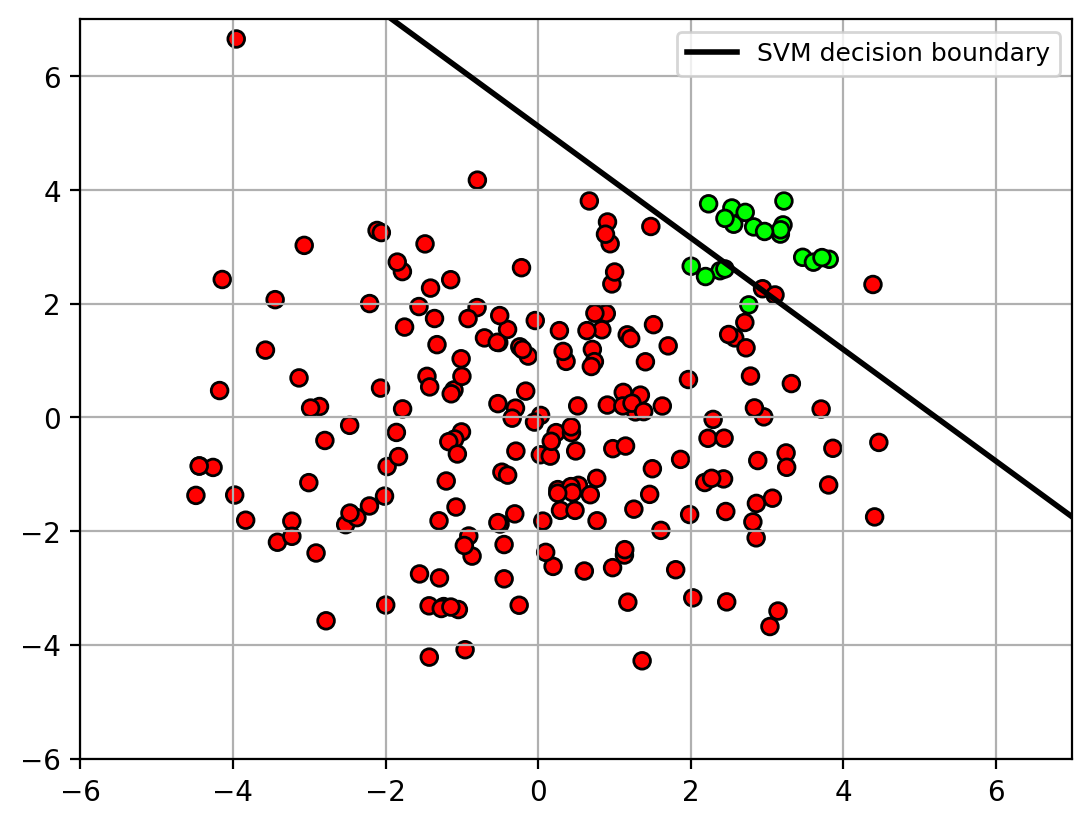
- Solution: apply weights on the classes during training.
- weights are inversely proportional to the class size.
1 | clfw = svm.SVC(kernel='linear', C=10, class_weight='balanced') |
class weights = [0.55 5.5 ]
1 | udatafig2 = plt.figure() |
1 | udatafig2 |
Classifier Imbalance
- In some tasks, errors on certain classes cannot be tolerated.
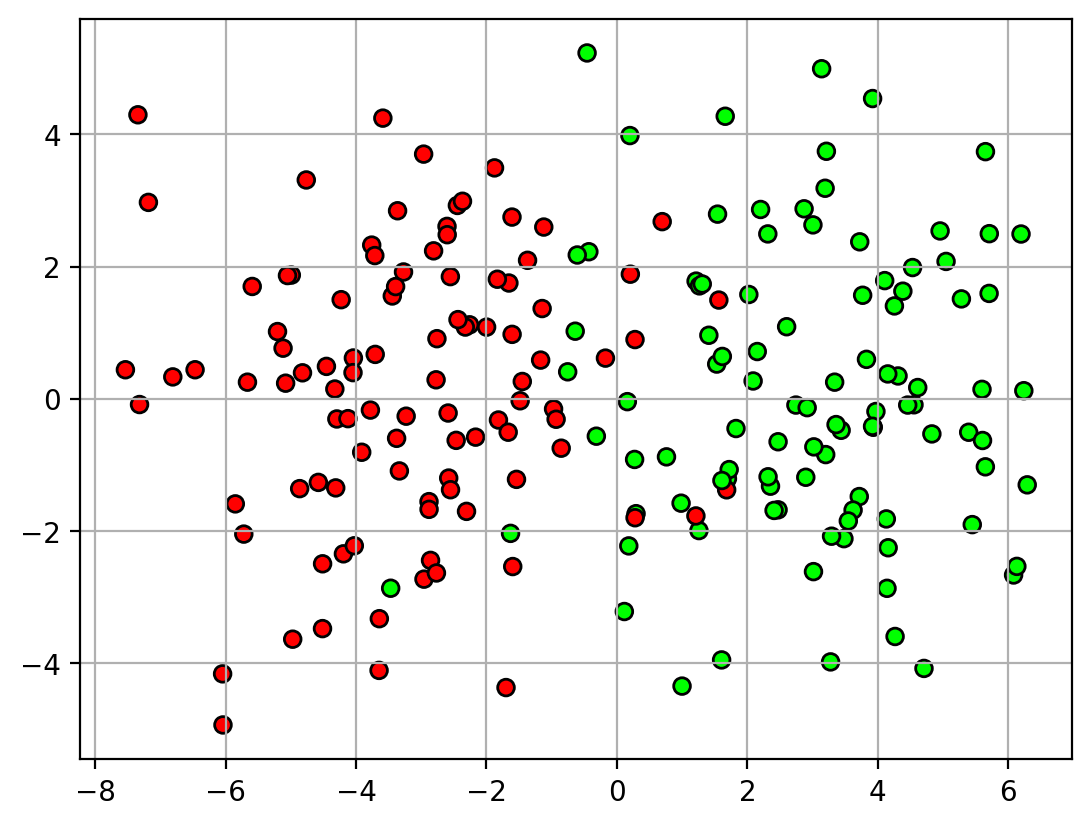
- Example: detecting spam vs non-spam
- non-spam should definitely not be marked as spam
- okay to mark some spam as non-spam
- non-spam should definitely not be marked as spam
1 | X,Y = datasets.make_blobs(n_samples=200, |
SVC(C=10, kernel='linear')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
SVC(C=10, kernel='linear')
1 | udatafig3 |
…
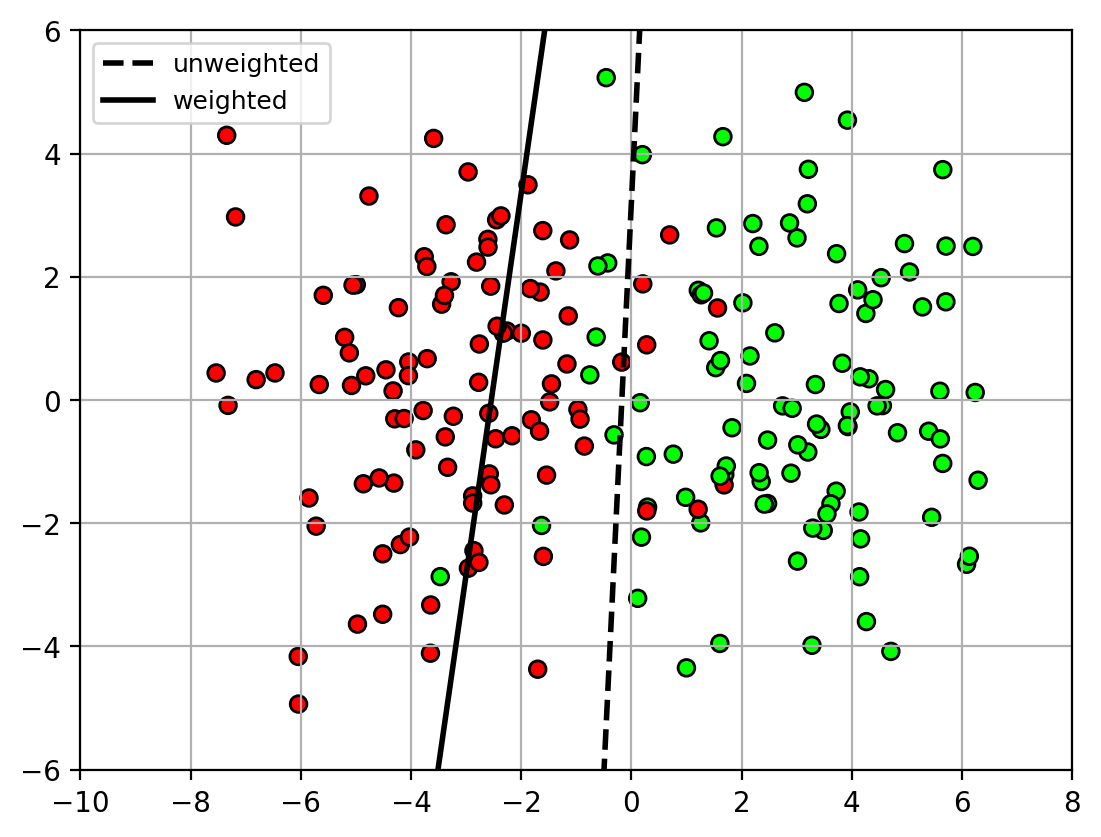
- Class weighting can be used to make the classifier focus on certain classes
- e.g., weight non-spam class higher than spam class
- classifier will try to correctly classify all non-spam samples, at the expense of making errors on spam samples.
- e.g., weight non-spam class higher than spam class
1 | # dictionary (key,value) = (class name, class weight) |
1 | udatafig4 = plt.figure() |
1 | udatafig4 |
…
Classification Summary
- Classification task
- Observation $\mathbf{x}$: typically a real vector of feature values, $\mathbf{x}\in\mathbb{R}^d$.
- Class $y$: from a set of possible classes, e.g., ${\cal Y} = {0,1}$
- Goal: given an observation $\mathbf{x}$, predict its class $y$.
| Name | Type | Classes | Decision function | Training | Advantages | Disadvantages |
|---|---|---|---|---|---|---|
| Bayes' classifier | generative | multi-class | non-linear | estimate class-conditional densities $p(x|y)$ by maximizing likelihood of data. | - works well with small amounts of data. - multi-class. - minimum probability of error if probability models are correct. |
- depends on the data correctly fitting the class-conditional. |
| logistic regression | discriminative | binary | linear | maximize likelihood of data in $p(y|x)$. | - well-calibrated probabilities. - efficient to learn. |
- linear decision boundary. - sensitive to $C$ parameter. |
| support vector machine (SVM) | discriminative | binary | linear | maximize the margin (distance between decision surface and closest point). | - works well in high-dimension. - good generalization. |
- linear decision boundary. - sensitive to $C$ parameter. |
| kernel SVM | discriminative | binary | non-linear (kernel function) | maximize the margin. | - non-linear decision boundary. - can be applied to non-vector data using appropriate kernel. |
- sensitive to kernel function and hyperparameters. - high memory usage for large datasets |
| AdaBoost | discriminative | binary | non-linear (ensemble of weak learners) | train successive weak learners to focus on misclassified points. | - non-linear decision boundary. can do feature selection. - good generalization. |
- sensitive to outliers. |
| XGBoost | discriminative | binary | non-linear (ensemble of decision trees) | train successive learners to focus on gradient of the loss. | - non-linear decision boundary. - good generalization. |
- sensitive to outliers. |
| Random Forest | discriminative | multi-class | non-linear (ensemble of decision trees) | aggregate predictions over several decision trees, trained using different subsets of data. | - non-linear decision boundary. can do feature selection. - good generalization. - fast |
- sensitive to outliers. |
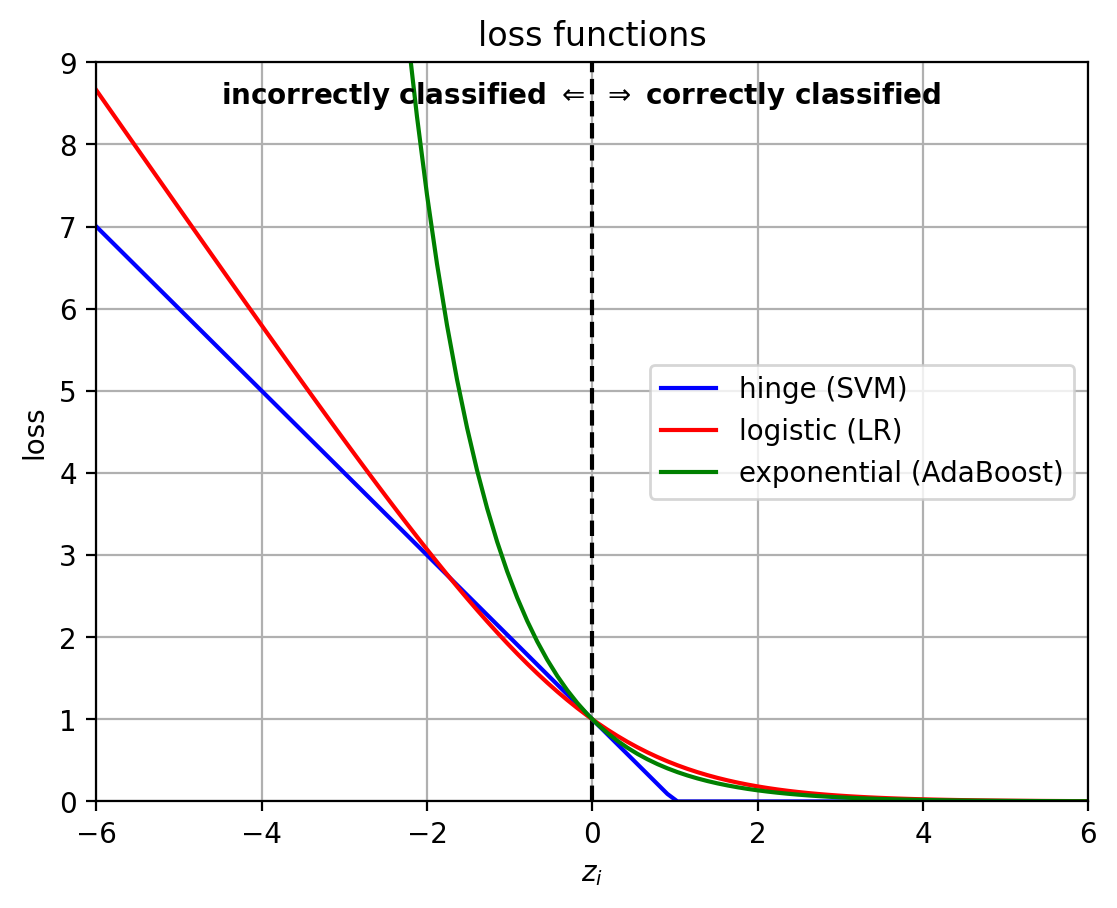
Loss functions
- The classifiers differ in their loss functions, which influence how they work.
- $z_i = y_i f(\mathbf{x}_i)$
1 | z = linspace(-6,6,100) |
1 | lossfig |
Regularization and Overfitting
- Some models have terms to prevent overfitting the training data.
- this can improve generalization to new data.
- There is a parameter to control the regularization effect.
- select this parameter using cross-validation on the training set.
1 | X,Y = datasets.make_blobs(n_samples=100, |
<Figure size 640x480 with 0 Axes>
1 | ofig |
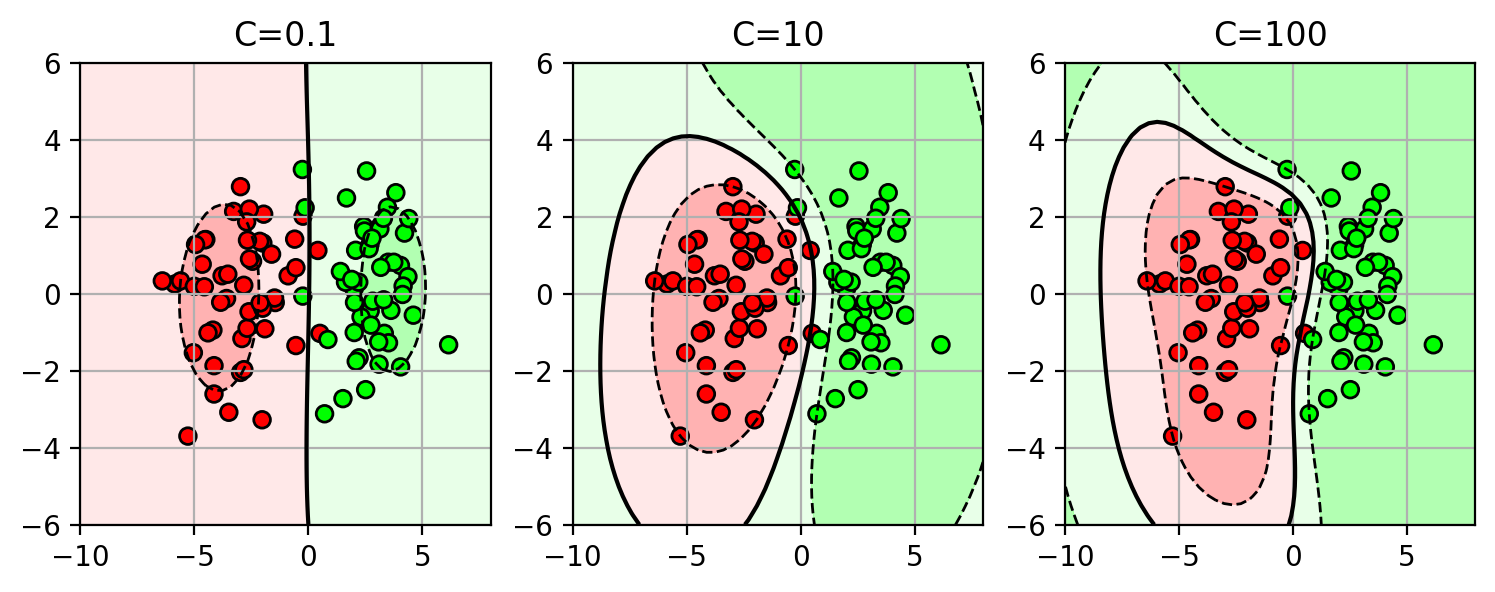
Structural Risk Minimization
- A general framework for balancing data fit and model complexity.
- Many learning problems can be written as a combination of data-fit and regularization term:
$$f^* = \mathop{\mathrm{argmin}}_{f} \sum_i L(y_i, f(\mathbf{x}_i)) + \lambda \Omega(f)$$- assume $f$ within some class of funcitions, e.g., linear functions $f(\mathbf{x}) = \mathbf{w}^T\mathbf{x}+b$.
- $L$ is the loss function, e.g., logistic loss.
- $\Omega$ is the regularization function on $f$, e.g., $||\mathbf{w}||^2$
- $\lambda$ is the tradeoff parameter, e.g., $1/C$.
Other things
- Multiclass classification
- can use binary classifiers to do multi-class using 1-vs-rest formulation.
- Feature normalization
- normalize each feature dimension so that some feature dimensions with larger ranges do not dominate the optimization process.
- Unbalanced data
- if more data in one class, then apply weights to each class to balance objectives.
- Class imbalance
- mistakes on some classes are more critical.
- reweight class to focus classifier on correctly predicting one class at the expense of others.
Applications
- Web document classification, spam classification
- Face gender recognition, face detection, digit classification
Features
- Choice of features is important!
- using uninformative features may confuse the classifier.
- use domain knowledge to pick the best features to extract from the data.
Which classifier is best?
- “No Free Lunch” Theorem (Wolpert and Macready)
“If an algorithm performs well on a certain class of problems then it necessarily pays for that with degraded performance on the set of all remaining problems.”
- In other words, there is no best classifier for all tasks. The best classifier depends on the particular problem.